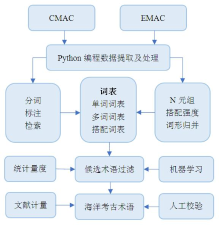
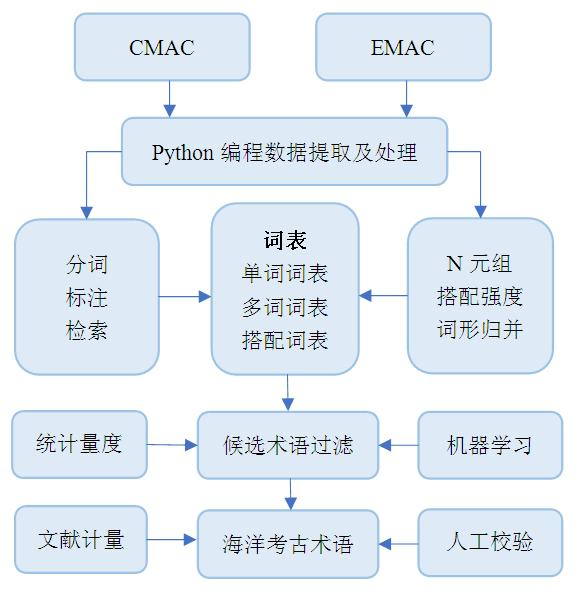
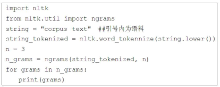
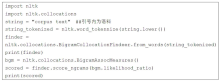
| [1] |
邱克. 浅谈海洋考古学[J]. 海交史研究, 1984:115-121,67.
|
| [2] |
冯志伟. 现代术语引论[M]. 增订本. 北京: 商务印书馆, 2011.
|
| [3] |
范依然. 南海考古资料整理与述评[M]. 北京: 科学出版社, 2013.
|
| [4] |
刘海涛. 中国语言学建设两大要务:成果国际化和方法科学化[J], 语言战略研究, 2018(1):37-50.
|
| [5] |
LEECH G. Principles and applications of Corpus Linguistics[C]//VIANA V, ZYNGIER S,BARNBROOK G. (eds.). Perspectives on Corpus Linguistics. Amsterdam: John Benjamins. 2011: 158.
|
| [6] |
PRITCHARD A. Statistical bibliography or bibliometrics?[J]. Journal of Documentation 1969, 25: 348-349.
|
| [7] |
季培培, 鄢小燕, 岑咏华. 面向领域中文文本信息处理的术语识别与抽取研究综述[J]. 图书情报工作, 2010, 54(16): 124-129.
|
| [8] |
PANTEL P, LIN D. A statistical corpus-based term extractor[C]// Proceedings of 14th Biennial Conference of the Canadian Society on Computational Studies of Intelligence:Advances in Artificial Intelligence. Berlin and Heidelberg: Springer-Verlag, 2001: 36-44.
|
| [9] |
张新, 党延忠. 基于规则与统计的本体概念自动获取方法研究[J]. 情报学报, 2007, 26(6): 813-820.
|
| [10] |
Jieba[CP/OL]. [2022-08-06]. https://github.com/fxsjy/jieba.
|
| [11] |
雷蕾. 基于Python的语料库数据处理[M]. 北京: 科学出版社, 2020.
|
| [12] |
张乐, 唐亮, 易绵竹. 融合多策略的军事领域中文术语抽取研究[J]. 现代计算机, 2020(26): 9-16,20.
|
| [13] |
FRANTZI K T, ANANIADOU S, MIMA H. Automatic Recognition of Multi-Word Terms: The C-Value/Nc-Value Method[J]. International Journal on Digital Libraries, 2000, 3(2): 115-130.
doi: 10.1007/s007999900023
URL
|
| [14] |
傅继彬, 樊孝忠, 毛金涛, 等. 基于语言特性的中文领域术语抽取算法[J]. 北京理工大学学报, 2010, 30(3): 307-310.
|
| [15] |
MANNING C D, SCHÜTZE H. Foundations of Statistical Natural Language Processing[M]. Cambridge: MIT Press, 1999.
|
| [16] |
黄友义. 坚持“外宣三贴近”,处理好外宣翻译中的难点问题[J]. 中国翻译, 2004, 25(6): 27-28.
|
| [17] |
中华人民共和国国家质量监督检验检疫总局,中国国家标准化管理委员会. 汉语拼音正词法基本规则:GB/T 16159—2012[S].
|
| [18] |
李宇明. 中国语言学的学科建设与发展规划[C]// 全国社科办语言学学科调研组《语言学新视野》. 北京: 商务印书馆, 2021.
|
| [19] |
陈新仁. 试论中国语用学学科话语体系的建构[J]. 外语教学, 2018 (5): 12-16.
|
| [20] |
王琪. 中国术语事业发展概况及思考[J]. 中国科技术语, 2021, 23(4): 3-7.
doi: 10.12339/j.issn.1673-8578.2021.04.001
|
 ), ZENG Gang(
), ZENG Gang(