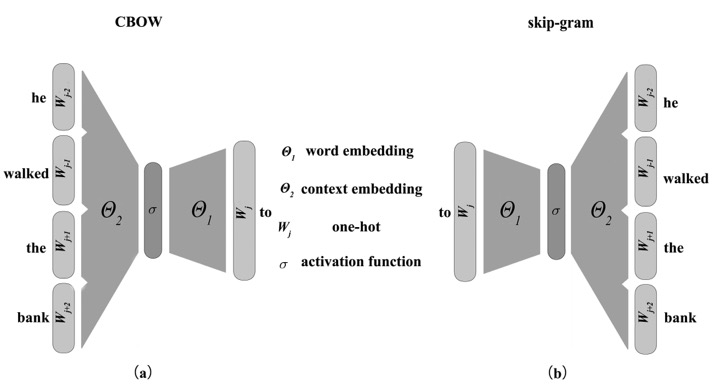
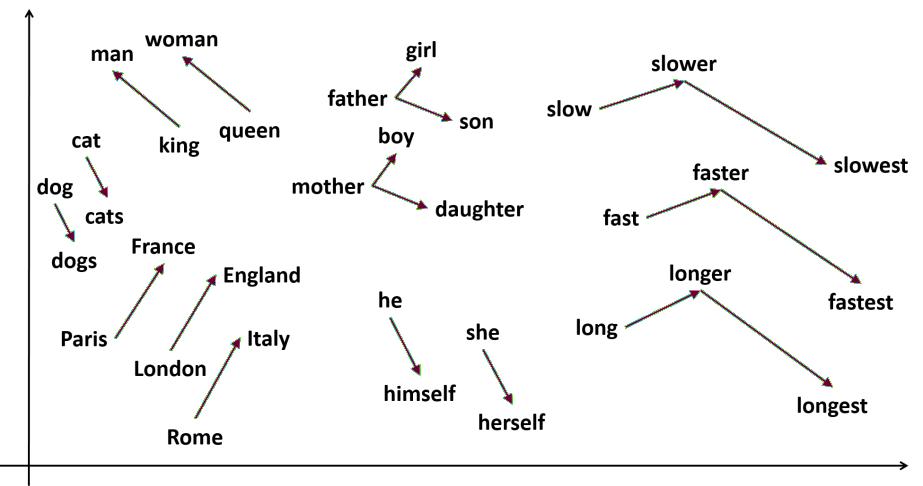
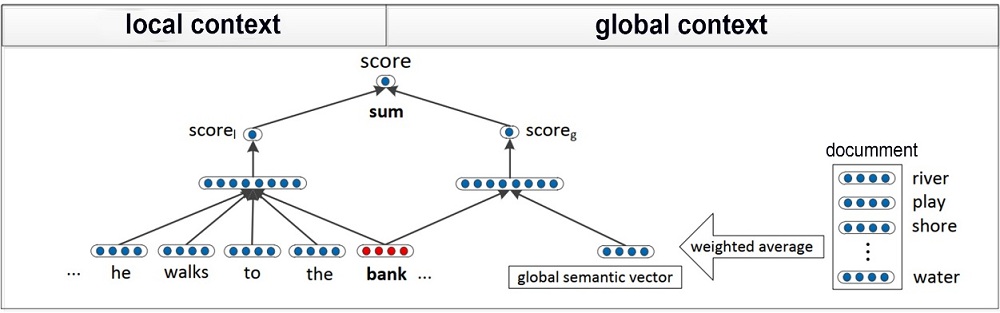
| [1] |
Hinton G E., Learning Distributed Representations of Concepts[C/OL]. [2020-05-17]. http://www.cs.toronto.edu/~hinton/absps/families.pdf.
|
| [2] |
Bengio Y, Ducharme R, Vincent P, et al. A Neural Probabilistic Language Model[J]. Journal of Machine Learning Research, 2003,3:1137-1155.
|
| [3] |
Harris Z S. Distributional Structure[J]. Word, 1954,10(2-3):146-162.
|
| [4] |
Firth J R. A Synopsis of Linguistic Theory, 1930—1955[J]. Studies in Linguistic Analysis, 1957, 168-205.
|
| [5] |
Li S, Zhao Z, Hu R, et al. Analogical reasoning on Chinese morphological and semantic relations[C/OL]. [2020-05-17]. https://arxiv.org/pdf/1805.06504.pdf.
|
| [6] |
Xu W, Rudnicky A. Can Artificial Neural Networks Learn Language Models?[C/OL]. [2020-05-17]. https://kilthub.cmu.edu/articles/Can_Artificial_Neural_Networks_Learn_Language_Models_/6604016/files/12094409.pdf.
|
| [7] |
Mikolov T, Sutskever I, Chen K, et al. Distributed Representations of Words and Phrases and Their Compositionality[C/OL]. [2020-05-17]. https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf.
|
| [8] |
Akhtar S S. Robust Representation Learning for Low Resource Languages[M]. INDIA: International Institute of Information Technology, 2018.
|
| [9] |
Reifler E. The Mechanical Determination of Meaning[J]. Readings in Machine Translation, 1955: 21-36.
|
| [10] |
Weaver W. Translation[J]. Machine Translation of Languages, 1955,14:15-23.
|
| [11] |
Weiss S F. Learning to disambiguate[J]. Information Storage and Retrieval, 1973,9(1):33-41.
|
| [12] |
Liu P, Qiu X, Huang X. Learning Context-sensitive Word Embeddings with Neural Tensor Skip-gram Model[C/OL]. [2020-05-17]. https://www.aaai.org/ocs/index.php/IJCAI/IJCAI15/paper/viewFile/11398/10841.
|
| [13] |
Li J, Jurafsky D. Do Multi-sense Embeddings Improve Natural Language Understanding?[C/OL]. [2020-05-17]. https://arxiv.org/pdf/1506.01070.
|
| [14] |
Huang E H, Socher R, Manning C D, et al. Improving Word Representations Via Global Context and Multiple Word Prototypes [C/OL]. [2020-05-17]. https://dl.acm.org/doi/pdf/10.5555/2390524.2390645?download=true.
|
| [15] |
Yu M, Dredze M. Improving Lexical Embeddings with Semantic Knowledge[C/OL]. [2020-05-17]. https://www.aclweb.org/anthology/P14-2089.pdf.
|
| [16] |
Bian J, Gao B, Liu T Y. Knowledge-powered Deep Learning for Word Embedding[C/OL]. [2020-05-17]. https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/5BECML20145D20Knowledge-Powered20Word20Embedding.pdf.
|
| [17] |
Nguyen K A, Walde S S, Vu N T. Integrating Distributional Lexical Contrast into Word Embeddings for Antonym-synonym Distinction [C/OL]. [2020-05-17]. https://arxiv.org/pdf/1605.07766.pdf.
|
| [18] |
Niu Y, Xie R, Liu Z, et al. Improved Word Representation Learning with Sememes[C/OL]. [2020-05-17]. https://www.aclweb.org/anthology/P17-1187.pdf.
|
| [19] |
Michel J B, Shen Y K, Aiden A P, et al. Quantitative Analysis of Culture Using Millions of Digitized Books[J]. Science, 2011,331(6014):176-182.
URL
pmid: 21163965
|
| [20] |
Bamman D, Crane G. Measuring Historical Word Sense Variation[C/OL]. [2020-05-17]. https://dl.acm.org/doi/pdf/10.1145/1998076.1998078.
|
| [21] |
Mihalcea R, Nastase V. Word Epoch Disambiguation: Finding How Words Change Over Time[C/OL]. [2020-05-17]. https://www.aclweb.org/anthology/P12-2051.pdf.
|
| [22] |
刘知远, 刘扬, 涂存超, 等. 词汇语义变化与社会变迁定量观测与分析[J]. 语言战略研究, 2016,1(6):47-54.
|
| [23] |
Hamilton W L, Leskovec J, Jurafsky D. Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change[C/OL]. [2020-05-17]. https://arxiv.org/pdf/1605.09096.pdf.
|