刘华杰
Liu Huajie
摘要: 中华民族几千年有赖文字之统一而凝聚为一个密不可分的群体。汉字具有不同于一般字母文字的强烈非线性特征,汉语字频统计发现,学习汉语比学习其它语言也许更容易些。本文分析了汉字字音的莱维(Paul Lévy)稳定分布和高频字分布规律,指出为了子孙后代学习和交流的方便,也为了汉语文化的发扬光大,应当联合包括台湾在内的广大华语世界尝试筛选制定一个4500字的左右的标准小字符集。
今天海峡两岸朋友在这里聚会,探讨如何迎接信息(information)时代的挑战。“信息”是大陆的叫法,在港台一般叫“资讯”。此外还有许多名词译法不同,如只读存储器与“唯读记忆体”,磁盘与“磁碟”,分形与“碎形”,等离子体与“电浆”等等。不能简单地说谁的叫法更好(各有长处),这种局面是长期以来大陆与海外语言文字和科学名词审定部门缺乏足够沟通的结果。现在海内外各种汉字信息交换字符集与代码标准相差甚远,此外还有汉字的简体与繁体等问题。本文探讨构造、筛选一种通用小字符集的可能性。
一、汉字的现状
中华民族是多民族的联合体,文化传承及国家统一都有赖于汉字的普遍使用和字形的长时期相对稳定。各地的人们说话尽可以南腔北调,但写出来却一个模样。但是近半个世纪,由于实施简化方案,汉字字形却发生了极大的变化。特别是祖国大陆与海外华人社会过去相当长时间内缺乏必要的沟通,汉字演化走向了不同的道路。随着信息社会的到来,大陆与台湾又各自独立地制定了不同的信息交换标准代码和基本字符集。大陆1980年制定国标字符集(GB2312-80),收字6700多个,其中一级字3755个,二级字2969个,二级字符中还有39个非字字符;台湾制定了大五码(BIG5),收字13500余个。后来又有了中、日、韩大字符集(CJK)和国际标准汉字大字符集的汉字输入方法的流行,以及新闻出版业告别铅排而百分之百依赖于计算机,汉字字符集对中华民族语言文字的影响已是至关重要的了。
发展到现在,海外沿用繁体字,大陆则大量使用简化字。海内外中文文字信息交流出现诸多不便,计算机汉字平台互不兼容(早期),在因特网(Internet)上阅读各自的文本也必须经过相应的转换,由于并非一一对应,转换中也出现了一些笑话,如“乾”与“干”。这种局面对汉语文化交流的长远影响值得关注。对于目前年龄在30岁以上的人,简繁的区分还不是本质上的,这些人对两种字形都还认识,而对年轻的朋友而言简繁的不同将是根本性的了。伴随信息时代的到来,海内外文字改革需要加强联系,增加共性,减少个性。一种长远的设想是建立一个大家都能接受的标准。我个人的初步想法是,构造一个通用的小字符集,简繁仍在相当长时间内保持并用局面。这种设想的必要性是:1)便于子孙后代学习汉字,发扬中华文化;2)适应信息社会信息的大量传输。下面着重谈可能性,分别从字音分布和字频分布考虑。
二、汉字字音的稳定分布特征
分形理论创始人芒德勃罗(B.B.Mandelbrot)早期曾从其老师莱维(Paul Lévy)那里学来“稳定分布”(stable distribution)的概念,并将它用于词频分布和收入分布研究,后来竟创立了分形科学。
稳定分布概念应该是概率论和随机过程理论中十分重要的内容,但现在许多教科书并不讲,我们知道布朗运动的基本思想是随机行走,所使用的基本数学是高斯正态分布。对于一维的N步随机行走,每一步的步长x是一随机变量,其概率分布为p(x),具有0均值。法国数学家莱维提出这样的问题:什么时候N步的总和的分布仍然具有与单步相似的(乘以一个标度因子)分布?这等于问,整体与部分何时有相似性,因而很自然与分形有关。对此问题通常的想当然的回答是高斯过程,因为N步高斯分布加起来仍然是高斯分布。但是莱维一般地证明了,此问题还有其他解。
早在1853年柯西(A.-L.Cauchy)就认识到对于N步可加(也叫稳定)随机过程,除了高斯分布作为其显然解外,还存在其他可能的解。当把x实空间变换为傅里叶(Fourier)k空间时,可加过程的可能概率分布为 N(k)=exp(-N|k|β)。当β等于1时,便得到柯西分布,β等于2时对应于高斯分布。如今上式称为莱维概率分布。
N(k)=exp(-N|k|β)。当β等于1时,便得到柯西分布,β等于2时对应于高斯分布。如今上式称为莱维概率分布。
应当说明的是,广义的莱维稳定过程(sD1+sD2=sD,s1X1+s2X2=sX+常数),仅对三种极特殊的情况,可以解析地求出稳定概率分布。当x的绝对值很大时,返回到实x空间,p(x)可以用|x|-1-β来近似。当β小于2时,显然p(x)的二阶矩无穷大。这意味着除了在高斯情形中,随机行走(飞行)没有特征尺度。正是这一性质决定此类随机行走是标度不变的分形。
今天我们用稳定分布和分形的观点考察汉字字符集,根据有关资料绘制了图1,图中有三条曲线,分别代表国标一级汉字、国标二级汉字和全体汉字(以《汉字信息字典》所收录的汉字代替)发音的首字母分布,三条曲线分别作了归一化处理,应作三点说明:1)图1以汉语拼音方案为准,但以其他注音方案统计,结果是一样的;2)在现代汉语拼音中I、U和V一般不作首字母出现,所以为0值;3)一级字样本数3755个,二级字样本数2969个,全部汉字样本数暂取11254个,后者大约是前者的3倍。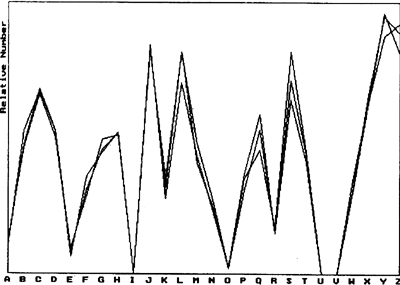
图1 三种汉字字符集的字音分布图
我们看到,三条曲线惊人地相似,归一化后差不多完全重合。这表明整体与部分之间只差一个标度因子,部分放大就是整体,整体缩小就是部分。换言之,大字符集与小字符集极其相似,部分可以一定意义上代替整体。
三、汉字字频分布特征
汉字是有别于字母文字的图形文字,造字原理东汉时许慎曾归纳为“六书”(象形、指事、会意、形声、转注、假借),其中又以“形声”字为主,大约占了80%。世界上许多文字最终都演化成字母文字,但汉字却基本没有什么变化。这种“停滞”值得研究,发展链条中止必有其内在原因。原因是什么?大概不止几条,但其一便是单字含义丰富,构词力强;其二便是汉字构成规律性强;其三是高频字相对于全部汉字而言极少。
第一、二点可用汉字的非线性解释,这里谈第三点。有三件事值得指出:1)现代意义上的汉字频率研究始于1921年陈鹤琴用统计方法考察白话文中汉字出现频度。2)1974年8月原四机部、一机部、中国科学院、国家出版局和新华社联合向国家计委申请“汉字信息处理系统工程”项目,对各种出版物进行了全面统计,样本达21657039字,将汉字按使用频度分布5级;最常用字500个,常用字500个,次常用字500个,稀用字1500个,冷僻字2991个。3)80年代初上海汉语拼音文字研究组和上海交大共同发起编撰《汉字信息字典》。
汉语似比英语、法语、德语难学,实际上未必。学英语掌握6000个单词只能算初级水平,许多材料无法看懂。但学汉语掌握1000个汉字就能读懂90%报刊文献资料。当然,不能仅仅作如此简单的对比,就得出汉语或汉字易学、具有优势的结论。但这是极重要的一个事实。
图2示意了前31个高频字的频度曲线。以千分比计,“的”字出现频率竟达38.3,“一”达12.5,“是”达9.8,“在”达9.4,“了”达8.1等等。北京大学力学系朱照宣先生将前5个字编成一句话:“是的,了一在。”它是对“王力先生在家吗?”问话的回答。“了一”为语言学家王力教授的“字”。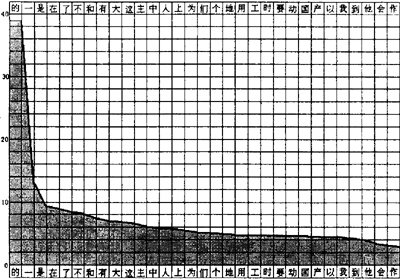
图2 前31个高频汉字相对频度图
前28个字(正好到“到”字)累计频率达到201,也就是说,从概率角度看,只要学会28个字,100个字中就有20个认识,就能“看懂”汉语文献的五分之一。学会100个字,就能“看懂”40%;学会160个字,就能“看懂”50%;一天学一个,一年学会365个汉字,就能看懂70%的汉语文献。学会950个汉字大约能看懂90%的汉语文献。国标一级字共有3755个,而累计频率达到99.69768%,这说明国标一级字有充分的代表性。
四、构造小字符集的可能性与困难
由以上两小节可知,汉字虽然成千上万,但现实生活中实际使用的汉字只是其中一个很小的子集,也许正是这一原因使得汉字非常适用于人们日常生活和文化交流。在现代信息社会,作为一个有文化的人究竟认识多少字才算合格呢?与人们朴素的想法相反,并不需要认识许多字,有5000字足够了。开始时我也不相信,后来仔细核对了国标一级字和二级字,发现二级字中相当多不认识,甚至从未见过,而我个人阅读中文文献从未遇到过困难,我写的文章用过的汉字大概不超过4000个。
那么一万多个汉字是作什么用的?20902个字符又是干什么的呢?我们不得不遗憾地说,这里面有一个很大的矛盾,是少数知识分子与广大平民百姓的矛盾。我们不妨看看字典中那些生僻的汉字,在现代社会只有极个别学究气十足的人故意使用大家都看不懂的文字,以显示学问的高深。从事中国古代文学、文化、文字等方面研究的,不在此列。为了适当照顾一些知识分子,短期内仍然可以有两套字符集并存,知识界用大字符集,普通百姓用小字符集。图书(特殊专业类图书除外)、广告、电视及其他大众媒体也应使用小字符集。
上面第2小节内容说明,采用小字符集,仍然能够保证汉语的语音特征,而且保持得非常好。第3小节说明绝大部分汉字均已死亡,它们的使用频率极低,去掉那些很少使用的汉字不会影响汉语的丰富性和表义的准确性。
海内外华人共商构造适用于信息社会的汉字小字符集的时机已经到来。采取的步骤可以是:1)海内外分别以大样本中文文献进行汉字信息统计分析;2)抛开意识形态因素,以汉字使用频率为主要指标筛选6000个通用汉字;3)海内外语言文字工作者协同商讨,将6000个汉字进一步缩减为4000~4500个;4)撇开频率因素,分类检查补漏,特别要考虑数字、计量单位、重要科学名词等;5)发布废止汉字及代替方案详表(如“吖”字完全可用“阿”取代,相应地“吖嗪”可用“阿秦”代替;“磲”用“渠”代替;“鄹”用“邹”代替;“蕞”用“最”代替等等);6)得到标准小字符集,在此基础上制定各种字模(如楷体、仿宋、报宋、综艺等)标准。鉴于大陆与海外简繁并用的现实,确定了小字符集后,严格规定简体与繁体,尽可能做到一一对应。
从技术角度看,上述步骤不存在任何困难。但从政治、经济、社会文化角度,从习惯甚至恶习的角度看,仍然存在许多难点。最大的麻烦可能来自少数学究的抵制和意识形态方面的干扰。北京航空航天大学的一位博士曾说:“老百姓使用白字、通假字具有天然合法性,“韭菜”就是要写作“艽菜”(注:“艽”字在字典上读“jiāo”,与韭菜没关系),汉字必须简化并且所用总字数也必须减少。”我们反对两种极端态度:1)汉字完美无缺无需改革;2)汉字一无是处应当废止。折衷的办法是筛选汉字标准小字符集。
五、问题
目前我们缺乏对海外中文文献的统计分析以及对海外各种内码方案及中文平台的发展状况的了解,迫切需要与台湾、香港、新加坡甚至洛杉矶,泰国等地语言文字工作者和信息处理部门合作研究。此外,还要科学地评估此种小字符集可能对社会文化产生的长期负面影响。本文作者非语言文字工作者,只是个人关心这方面的话题 ,不当之处恳请批评。
感谢北京大学物理系赵凯华教授和力学系朱照宣教授、北京理工大学孔昭君副教授提供有关资料和意见。
图1 三种汉字字符集的字音分布图; 图2 前31个高频汉字相对频度图
* 本文为1997年10月19日—26日海峡两岸青年学者论坛——迎接信息时代挑战学术研讨会论文,南京。