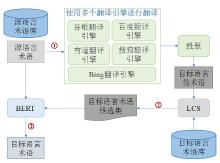
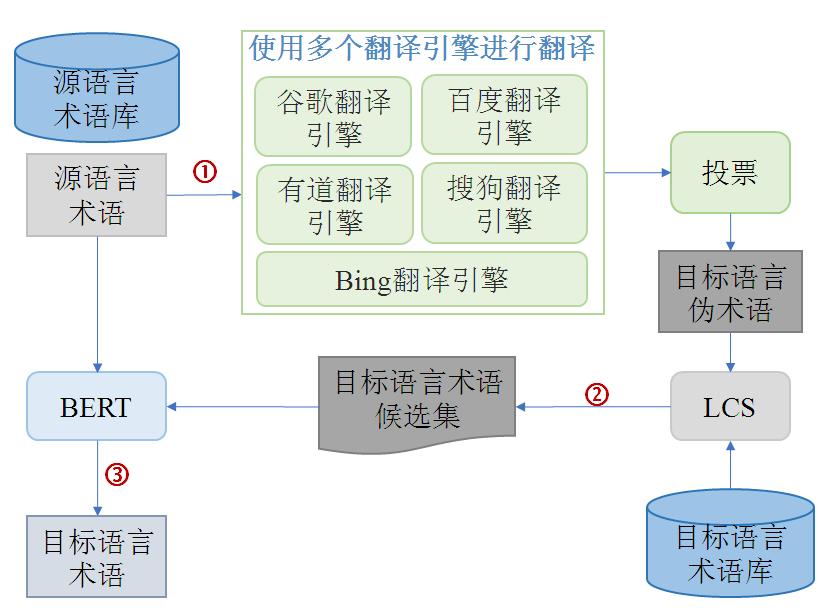
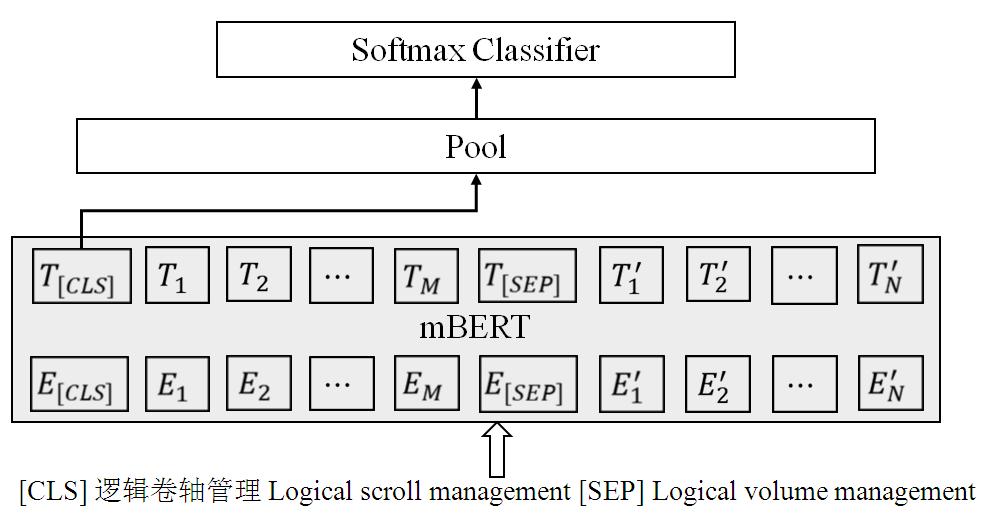
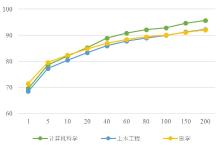
| [1] |
冯志伟. 现代术语学引论[M]. 北京: 语文出版社, 1997.
|
| [2] |
杜波, 田怀凤, 王立, 等. 基于多策略的专业领域术语抽取器的设计[J]. 计算机工程, 2005(14):159-160.
|
| [3] |
孙茂松, 李莉, 刘知远. 面向中英平行专利的双语术语自动抽取[J]. 清华大学学报(自然科学版), 2014, 54(10):1339-1343.
|
| [4] |
孙乐, 金友兵, 杜林, 等. 平行语料库中双语术语词典的自动抽取[J]. 中文信息学报, 2000(6):33-39.
|
| [5] |
HUANG G P, ZHANG J J, ZHOU Y, et al. A simple, straightforward and effective model for joint bilingual terms detection and word alignment in smt[C]//Proceedings of the Fifth Conference on Natural Language Processing and Chinese Computing & The Twenty Fourth International Conference on Computer Processing of Oriental Languages. Kunming, China, 2016:103-115.
|
| [6] |
LEFEVER E, MACKEN L, HOSTE V. Language-independent bilingual terminology extraction from a multilingual parallel corpus:A simple, straightforward and effective model for joint bilingual terms detection and word alignment in smt[C]// Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009). 2009: 496-504.
|
| [7] |
FAN X, SHIMIZU N, NAKAGAWA H. Automatic extraction of bilingual terms from a chinese-japanese parallel corpus[C]// Proceedings of the 3rd International Universal Communication Symposium. 2009: 41-45.
|
| [8] |
蒋俊梅. 基于平行语料库的双语术语抽取系统研究[J]. 现代电子技术, 2016, 39(15):108-111.
|
| [9] |
康小丽, 章成志, 王惠临. 基于可比语料库的双语术语抽取研究述评[J]. 现代图书情报技术, 2009(10):7-13.
|
| [10] |
AKER A, PARAMITA M L, GAIZAUSKAS R. Extracting bilingual terminologies from comparable corpora[C]// Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Sofia, Bulgaria: Association for Computational Linguistics, 2013:402-411.
|
| [11] |
张雪, 孙宏宇, 辛东兴, 等. 自动术语抽取研究综述[J]. 软件学报, 2020, 31(7):2062-2094.
|
| [12] |
李思良, 许斌, 杨玉基. DRTE:面向基础教育的术语抽取方法[J]. 中文信息学报, 2018, 32(3):101-109.
|
| [13] |
CRAM D, DAILLE B. Termsuit: Terminology extraction with term variant detection[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Berlin, Germany: Association for Computational Linguistics, 2016:13-18.
|
| [14] |
ZHANG Z, GAO J, CIRAVEGNA F. Semre-rank: Improving automatic term extraction by incorporating semantic relatedness with personalised pagerank[J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2018, 12(5):1-41.
|
| [15] |
DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Minneapolis, Minnesota: Association for Computational Linguistics, 2019:4171-4186.
|
| [16] |
BOURIGAULT D, GONZALEZ-MULLIER I, GROS C. Lexter, a natural language processing tool for terminology extraction[C]//Proceedings of the 7th EURALEX International Congress. Göteborg, Sweden: Novum Grafiska AB, 1996: 771-779.
|
| [17] |
JUSTESON J S, KATZ S M. Technical terminology: some linguistic properties and an algorithm for identification in text[J]. Natural language engineering, 1995, 1(1):9-27.
doi: 10.1017/S1351324900000048
URL
|
| [18] |
化柏林. 针对中文学术文献的情报方法术语抽取[J]. 现代图书情报技术, 2013 (6):68-75.
|
| [19] |
祝清松, 冷伏海. 自动术语识别存在的问题及发展趋势综述[J]. 图书情报工作, 2012, 56(18):104-109.
|
| [20] |
向音, 李苏鸣. 领域术语特征分析:以军语为例[J]. 中国科技术语, 2012, 14(5):5-9.
|
| [21] |
张乐, 唐亮, 易绵竹. 融合多策略的军事领域中文术语抽取研究[J]. 现代计算机, 2020(26):9-16,20.
|
| [22] |
屈鹏, 王惠临. 面向信息分析的专利术语抽取研究[J]. 图书情报工作, 2013, 57(1):130-135.
|
| [23] |
曾文, 徐硕, 张运良, 等. 科技文献术语的自动抽取技术研究与分析[J]. 现代图书情报技术, 2014(1):51-55.
|
| [24] |
胡阿沛, 张静, 刘俊丽. 基于改进C-value方法的中文术语抽取[J]. 现代图书情报技术, 2013(2):24-29.
|
| [25] |
JONES K S. A statistical interpretation of term specificity and its application in retrieval[J]. Journal of documentation, 2004.
|
| [26] |
CAMPOS R, MANGARAVITE V, PASQUALI A, et al. A text feature based automatic keyword extraction method for single documents[C]//European conference on information retrieval. Grenoble, France: Springer International Publishing, 2018:684-691.
|
| [27] |
VU T, AW A, ZHANG M. Term extraction through unithood and termhood unification[C]// Proceedings of the Third International Joint Conference on Natural Language Processing: Volume-II. 2008: 631-636.
|
| [28] |
贾美英, 杨炳儒, 郑德权, 等. 采用CRF技术的军事情报术语自动抽取研究[J]. 计算机工程与应用, 2009, 45(32):126-129.
|
| [29] |
刘辉, 刘耀. 基于条件随机场的专利术语抽取[J]. 数字图书馆论坛, 2014(12):46-49.
|
| [30] |
KUCZA M, NIEHUES J, ZENKEL T, et al. Term extraction via neural sequence labeling a comparative evaluation of strategies using recurrent neural networks[C]// 19th Annual Conference of the International Speech Communication Association. Hyderabad, India: ISCA, 2018: 2072-2076.
|
| [31] |
HAZEM A, BOUHANDI M, BOUDIN F, et al. Termeval 2020: Taln-ls2n system for automatic term extraction[C]//Proceedings of the 6th International Workshop on Computational Terminology. Marseille, France: European Language Resources Association, 2020:95-100.
|
| [32] |
SEMMAR N. A hybrid approach for automatic extraction of bilingual multiword expressions from parallel corpora[C]//Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). Miyazaki, Japan: European Language Resources Association (ELRA), 2018: 311-318.
|
| [33] |
REPAR A, PODPECAN V, VAVPETIC A, et al. Termensembler: An ensemble learning approach to bilingual term extraction and alignment[J]. Terminology. International Journal of Theoretical and Applied Issues in Specialized Communication, 2019, 25(1):93-120.
doi: 10.1075/term
URL
|
| [34] |
HAZEM A, MORIN E. Efficient data selection for bilingual terminology extraction from comparable corpora[C]//Proceedings of 26th International Conference on Computational Linguistics: Technical Papers (COLING). Osaka, Japan: The COLING 2016 Organizing Committee, 2016: 3401-3411.
|
| [35] |
KONTONATSIOS G, KORKONTZELOS I, TSUJII J, et al. Combining string and context similarity for bilingual term alignment from comparable corpora[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Doha, Qatar: Association for Computational Linguistics, 2014: 1701-1712.
|
| [36] |
DAILLE B, MORIN E. French-English terminology extraction from comparable corpora[C]//Second International Joint Conference on Natural Language Processing: Full Papers. Berlin, Heidelberg: Springer, 2005: 707-718.
|
| [37] |
张莉, 刘昱显. 基于语序位置特征的汉英术语对自动抽取研究[J]. 南京大学学报(自然科学), 2015, 51(4):707-713.
|
| [38] |
刘胜奇, 朱东华. 基于多策略融合Giza++的术语对齐法[J]. 软件学报, 2015, 26(7):1650-1661.
|
| [39] |
RAPP R. Identifying word translations in non-parallel texts[C]//Proceedings of the 33rd Annual Meeting of the Association for Computational Linguistics. Cambridge, Massachusetts, USA: Association for Computational Linguistics, 1995:320-322.
|
| [40] |
TANAKA K, IWASAKI H. Extraction of lexical translations from non-aligned corpora[C]//Proceedings of the 16th International Conference on Computational Linguistics. Copenhagen, Denmark. 1996:580-585.
|
| [41] |
YU K, TSUJII J. Extracting bilingual dictionary from comparable corpora with dependency heterogeneity[C]//Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics, Companion Volume: Short Papers. Boulder, Colorado: Association for Computational Linguistics, 2009: 121-124.
|
| [42] |
LEE L, AW A, ZHANG M, et al. Em-based hybrid model for bilingual terminology extraction from comparable corpora[C]//Proceedings of the 23rd International Conference on Computational Linguistics. Beijing, China:Coling 2010 Organizing Committee, 2010: 639-646.
|
| [43] |
LIU Y, OTT M, GOYAL N, et al. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 2019.
|
| [44] |
BAKKELUND D. An lcs-based string metric[J]. Olso, Norway: University of Oslo, 2009.
|
| [45] |
宗成庆. 统计自然语言处理[M]. 北京: 清华大学出版社, 2013.
|
 ), 周玉1,2,3(
), 周玉1,2,3(