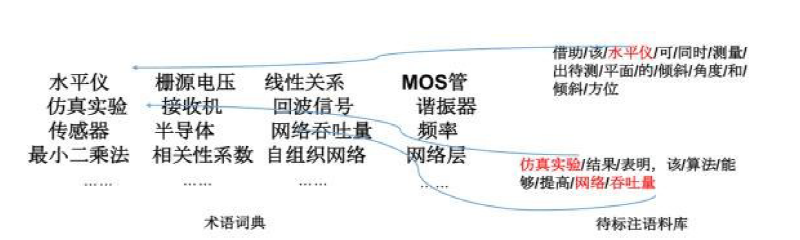
| [1] |
KAGEURA K, UMINO B. Methods of Automatic Term Recognition[J]. Terminology , 1996,3(2):29-35.
|
| [2] |
PANTEL P, LIN D. A Statistical Corpus-Based Term Extractor[M]//STUMPTNER M, CORBETT D, BROOKS M. Advances in Artificial Intelligence. Berlin Heidelberg: Springer-Verlag, 2001: 36-46.
|
| [3] |
HISAMITSU T, NIWA Y, TSUJII J. A method of measuring term representativeness baseline method using co-occurrence distribution[C]. COLING, 2000: 320-326.
|
| [4] |
CHANG J S. Domain specific word extraction from hierarchical web documents: a first step toward building lexicon trees from web corpora[C]// Proceedings of the 4th SIGHAN Workshop on Chinese Language Learning: 64-71.
|
| [5] |
FRANTZI K, ANANIADOU S, MIMA H. Automatic recognition of multi-word terms: the C value/NC-value method[J]. International Journal on Digital Libraries, 2000,3(2):115-130.
doi: 10.1007/s007999900023
URL
|
| [6] |
NAKAGAWA H, MORI T. A simple but powerful automatic term extraction method[C]//Proceedings of 2nd International Workshop on Computational Terminology. COLING-2002 WORKSHOP, 2002,109(4):229-30.
|
| [7] |
WERMTER , JOACHIM , HAHN , et al. Paradigmatic modifiability statistics for the extraction of complex multi-word terms[J]. Proceedings of HLT-EMNLP’05, 2005: 843-850.
|
| [8] |
JU Z, ZHOU M, ZHU F. Identifying biological terms from text by support vector machine[J]. Industrial Electronics and Applications, 2011: 455-458.
|
| [9] |
ZHANG X, SONG Y, FANG A C. Term recognition using Conditional Random fields[J]. International Conference on Natural Language Processing and Knowledge Engineering, 2010: 1-6.
|
| [10] |
LI S, LI J, SONG T, et al. A novel topic model for automatic term extraction[C]// Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval (SIGIR’13). 2013: 885-888.
|
| [11] |
MINTZ M, BILLS S, SNOW R, et al. Distant supervision for relation extraction without labeled data[C]. Meeting of the association for computational linguistics, 2009: 1003-1011.
|
| [12] |
word2vec project.[EB/OL].(2013-07-30)[2020-04-07]. https://code.google.com/p/word2vec.
|
| [13] |
CRF++: Yet Another CRF toolkit.[EB/OL].(2013-02-13)[2020-04-08]. http://taku910.github.io/crfpp.
|
 ), 张浩2(
), 张浩2(